1. 低识别率问题出现的常见原因
- 语音识别模型没有经过训练,或者模型训练未完成。
没有进行机器学习训练或没有得到充分训练的模型一般不可能正确地完成任何任务。如果已经完成训练过模型,或者使用其他人训练完毕的模型,请首先加载模型参数文件。 - 训练使用的语音数据集与您目标应用场景需求不匹配。
如果训练使用的是中文普通话数据集,但是您想识别任何英文文本,都是几乎不可能的。同样,词汇、口音、方言、是否包含噪声、是否为二次转录或转码等多种变量的不同(不匹配)都会导致低识别率问题。 - 声音数据在信息传输过程中出现错误。
例如,您使用GBK编码数据但是使用UTF-8进行解码,会造成数据错误。或者将错误格式的数据传输给了神经网络模型。
2. 排查语音识别错误的步骤
先使用cooledit或者Adobe Audition打开查看语音格式,播放试听并查看分轨情况、波形、能量和频谱图。ASRT识别的标准格式是:wav格式(PCM和RAW均可)、16KHz采样率、16bit采样位数、单声道的语音数据(在使evaluate_speech_model.py程序评估模型识别错误率的时候,可使用双声道语音数据)。
3. 检查使用的录音的质量
听:播放声音进行试听。
一听是否存在噪音,若存在,是人噪(人发出的声音或者远场非主说话人的声音)还是非人噪(如敲桌子、开门、汽车鸣笛等)。有些录音设备在录制声音的时候存在大量的噪音,如电流声。
二听是否发音清晰、是否可以听清或辨识度高,是否存在吞音、过于快语速或者重口音、方言等(切记主观语义判断,以听为主进行判断)。人无法正常听清楚并正确辨别的语音,一般来说也不能指望机器能够正确识别。
三听录音是否为二次或多次以上转录出来的声音,而不是人声直接录制的,二次转录的录音由于音频质量较差,中间产生的噪声较多,模型很难正确识别出来。建议直接使用直接由人声录制出的音频进行识别,而不是转录。
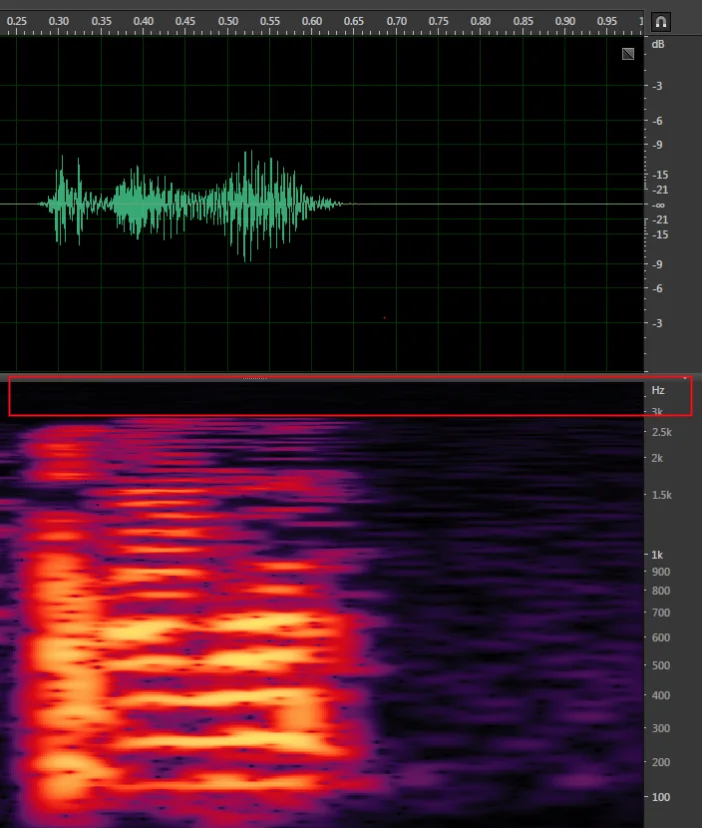
看:查看波形、能量和频谱图,对于录音文件识别服务,查看分轨情况
一看波形幅度是否过小或过大。以8KHz语音为例,图0为正常语音波形;图1为波形幅度不大,说话声音能量过低;图2为波形幅度过大,有可能截幅,超出系统的线性范围。下图为正常语音波形(绿色部分)和频域信息(红色部分):
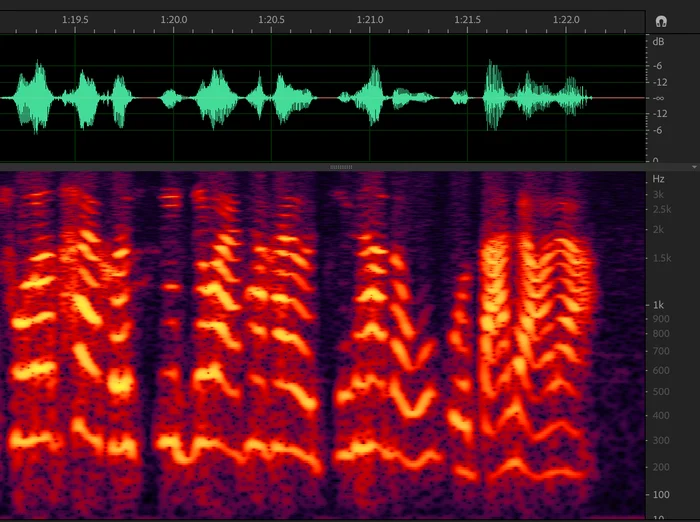
下图为波形幅度过小,说话声音能量过低:
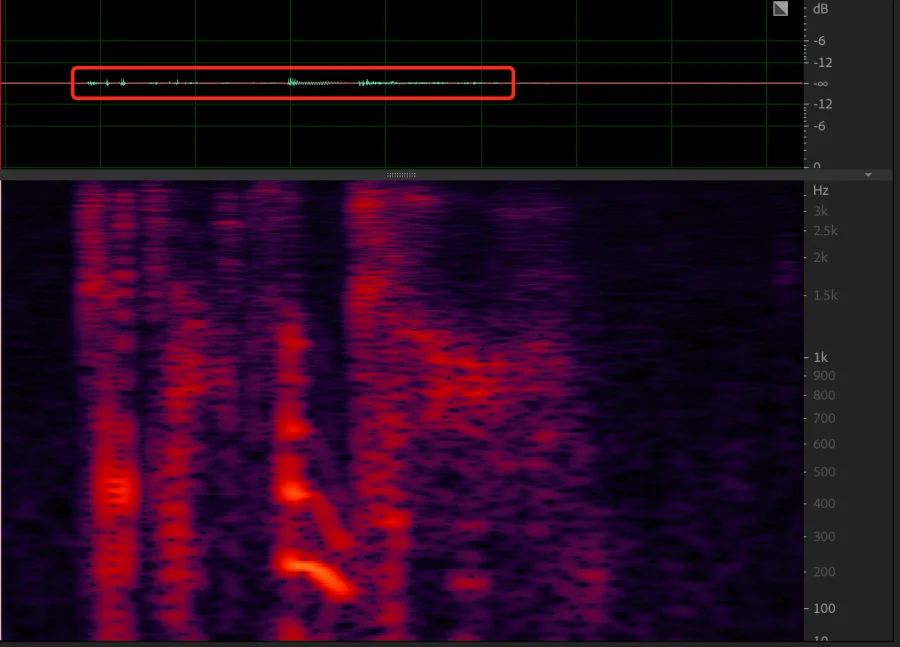
下图为波形幅度过大,有可能截幅,超出系统的线性范围:
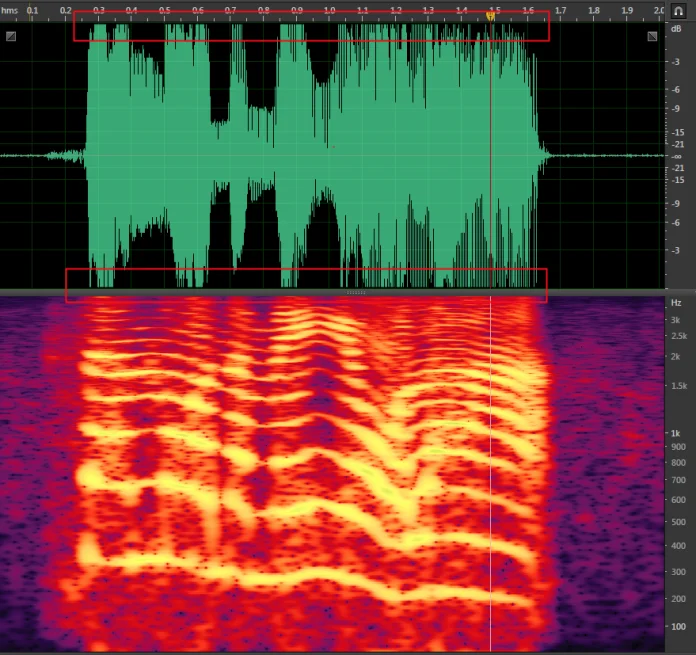
- 二看频段信息,是否是音段信息完整的8K或16K数据(频段对应数字乘以2是实际多少K的数据)。下图为数据格式虽为8K数据,实际频段信息只有3*2=6K,6K以上频域信息丢失。
对于使用录音数据集在测试函数上直接测试的,或者使用predict_speech_file.py程序直接识别一个录音文件的,三看是合轨数据还是分轨数据(以客服场景为例,合轨指客户和客服的声音存在一个声道,不免会有语音重叠的时刻。分轨指客户和客服两个声道的声音分开存储在两个声道)。
- 查:检查wav文件格式是否规范,有的wav格式文件在文件头部缺少格式信息,或者格式不规范,或者文件头部信息有错误。可使用相关软件进行查看,对于懂16进制数计算和wav文件格式标准的用户来说,可以直接使用二进制文件查看器进行查看,比如HxD。
4. 语音识别结果错误的解决方案
说明: 语音识别不可能达到100%识别准确,不是所有的badcase都能解掉。
如果有特定识别场景需求,请使用特定场景下的数据集自行训练声学模型和语言模型。
以上吞音、辨识度不高、听不懂等情况无法解决,听不清无法认定是ASR的识别错误。
如果是存在方言和重口音等,有可能是训练数据覆盖不全造成识别错误。
如果有大量的重口音(非方言)识别需求,或者8kHz采样率的wav文件识别需求,请自行使用特定数据集训练模型。如果需要帮助,针对特定需求修改代码,请联系AI柠檬博主。
如果是波形幅度不大,能量过低,造成识别丢失,有可能声音太小被模型当成噪声处理掉,建议调整录音设备,或者说话人离录音设备近些。
如果是波形幅度过大,能量过高,造成识别错误,有可能声音太大截幅,语音失真造成识别错误。建议调整录音设备,或者说话人离录音设备远些。
如果是因为频段信息不完整,有可能会造成识别不准确,ASRT模型的标准训练数据为频段完整的16K数据。建议您确认是否可以存储频段完整的16K数据,另外建议对识别不准的语料进行微调finetune优化。
如果存在特定词的拼音识别正确,但转换为汉字时错误的问题,则可以在language_model2.txt文件里面添加对应的词并设置权重,或调高2字词权重即可。
如果音频是多说话人的合轨数据,两个人说话重叠会造成识别不准确,此问题ASR无法解决,建议采用分轨进行存储。
如果以上条件都不符合,或者尚未能解决您的问题,请加入AI柠檬博主的QQ群进行讨论,大家集思广益,互相学习,共同进步,群号见本文档首页。
提问时,请尽量提供识别有问题的语音数据,以及该数据的正确识别结果和错误识别结果,简单描述下识别问题。
更新时间:2026-04-10 01:42
